 Whitepapers
Whitepapers
Roadmap zur AI-Plattform: Ihre 5-Schritte-Anleitung mit Beispielen und Checklisten



4 Min. Lesezeit

Erinnern Sie sich noch an DeepSeek R1 im Januar 2025? Damals hatte ein chinesisches Modell große Aufmerksamkeit in den Medien bekommen.
Bemerkenswert war daran nicht nur die Leistung, sondern vor allem der Zeitpunkt: Nur rund fünf Monate nachdem OpenAI mit o1-preview das erste große Reasoning-Modell vorgestellt hatte, erschien mit DeepSeek R1 das erste ernsthafte offene Reasoning-Modell. DeepSeek gab später an, dass das Training von R1 nur rund 294.000 US-Dollar gekostet habe. Die Nachricht erschütterte sogar die Börsen: Nvidia verlor am 27. Januar 2025 fast 600 Milliarden US-Dollar an Marktwert, weil Investoren plötzlich infrage stellten, ob für KI wirklich immer noch immer mehr und immer teurere GPUs nötig sind.
In der Praxis führen solche Optimierungen allerdings selten zu weniger Rechenbedarf. Meist werden die Effizienzgewinne sofort in noch größere Modelle gesteckt, denn die KI-Revolution scheint vor allem eines nicht zu haben: genug Rechenleistung.
Seitdem ist es hierzulande in den großen Medien um die chinesischen Modelle wieder stiller geworden. In Wirklichkeit läuft das Rennen jedoch ungebrochen weiter und ist spannend.
Jensen Huang, der CEO von NVIDIA, warnte bereits im November:
As I have long said, China is nanoseconds behind America in AI.
Und tatsächlich: Das neueste DeepSeek-Modell V4 zeigt, wie klein der Abstand geworden ist. In vielen bekannten Benchmarks liegt es nahe an führenden US-Modellen:
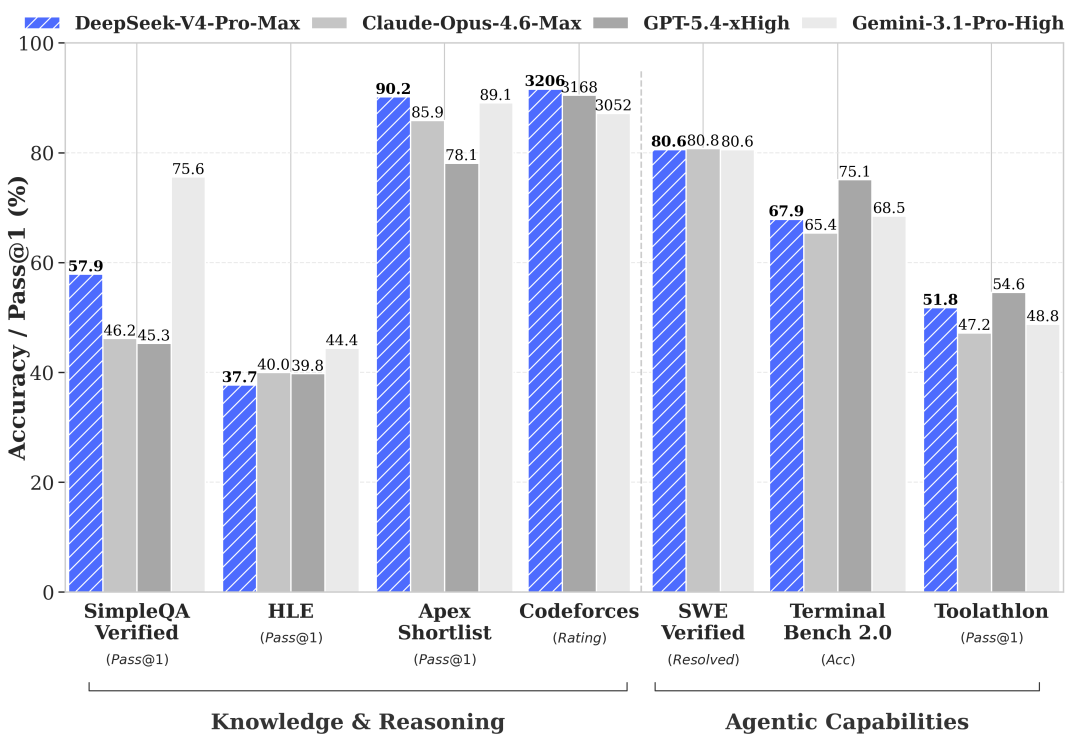
Aber stimmt das wirklich?
Viele werfen den chinesischen Modellen „Bench-Maxxing“ vor, also ein gezieltes Training auf Benchmarks. Echte Beweise dafür liefern sie allerdings meist nicht. In unabhängigen Benchmarks, deren Testdaten nicht öffentlich zugänglich sind, etwa Simple-Bench oder ARC-AGI 1, erreichen die chinesischen Modelle Werte im Mittelfeld. Auch in meinen eigenen Benchmarks kommen sie über die ersten Hürden. Bei Coding-Aufgaben, die vielleicht fünf Minuten dauern, sind sie kaum von den großen amerikanischen Modellen zu unterscheiden.
Auf dem Markt der einfachen Chatbots, wie sie etwa OpenAI, Anthropic und Google auf ihren Webseiten anbieten, sind sie jedenfalls ebenbürtig. Der klassische Chatbot für Rechtschreibkorrekturen, Stilvorschläge oder einfache Fragen ist damit zunehmend austauschbar geworden.
Wie weit China inzwischen ist, lässt sich auch abschätzen, wenn man sich die Größe der dortigen Top-Modelle ansieht. In der Tabelle steht die Firma, gefolgt von dem Modellnamen und der Größe des Modells. „B“ steht hier für Milliarden Parameter und „T" für Billionen (T=1000B).
Bereits drei dieser Modelle erreichen die Größenordnung von einer Billion Parametern. Der Vergleich mit amerikanischen Modellen ist aber schwierig, weil dort meist keine offiziellen Zahlen veröffentlicht werden.
Die letzte Schätzung stammt von einem Forscher der Firma Pine AI. Dafür wurde ein Test aus sehr vielen faktischen Wissensfragen gebaut, bei denen sich die Antwort kaum logisch herleiten lässt. Man muss sie entweder im Modell gespeichert haben oder eben nicht. Es geht dabei zum Beispiel um sehr obskure Fakten, Namen oder Details.
Die Grundidee dahinter lautet: Je größer ein Modell ist, desto mehr schwer komprimierbares Wissen kann es speichern. Auf Basis der Modelle mit bekannter Parameteranzahl kommt er auf folgende Schätzung:
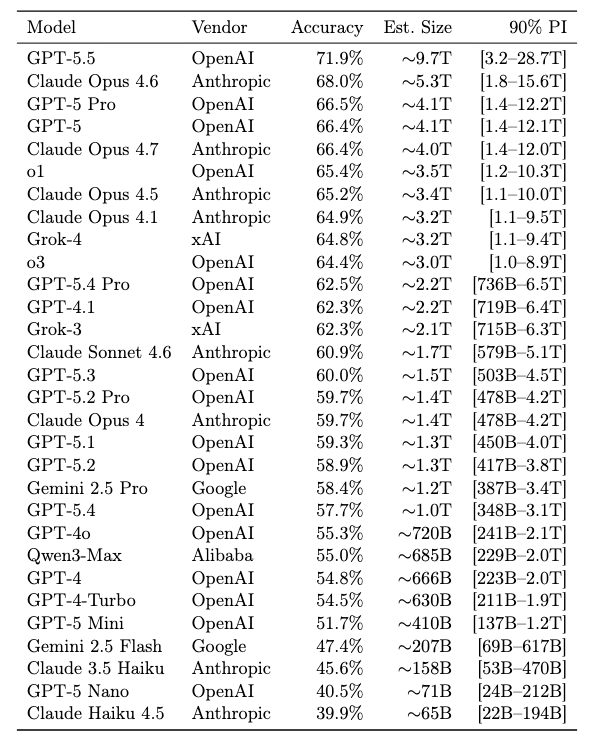
Geschätzte Modellgrößen der großen amerikanischen Modelle. Die Top-Modelle erreichen wenigstens 2000 Milliarde Parameter.
Diese Liste sollte man natürlich mit Zweifeln betrachten. Laut Elon Musk hat zum Beispiel Grok-4 nur eine Größe von maximal 0.5T.
Die Schätzung liegt also um den Faktor 6 daneben. Sonnet 4 von Anthropic soll laut Musk außerdem grob 1T Parameter haben, Opus etwa 5T Parameter. Hier scheinen die Schätzungen also ungefähr zu passen. Woher Musk das weiß? Anthropic hatte sich bei xAI kürzlich Rechenkapazität von 220.000 NVIDIA-GPUs gesichert. Die Größe der Modelle dürfte daher bekannt sein.
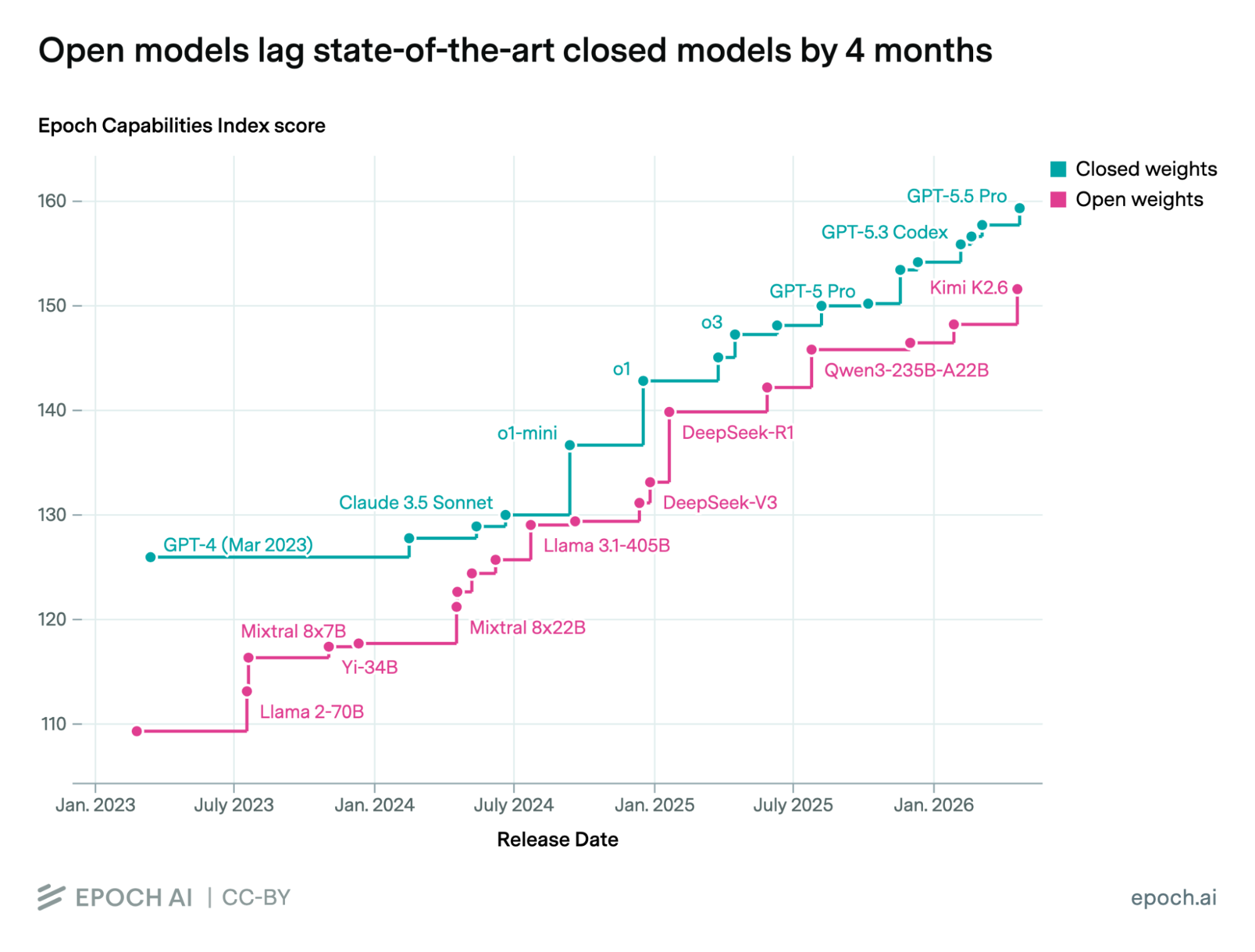
Insgesamt zeigt sich also: Abgesehen von den wenigen in diesem Jahr erschienenen Top-Modellen von OpenAI und Anthropic sind die chinesischen Modelle gleichauf; ihr Rückstand beträgt höchstens ein halbes Jahr.
Dies wird auch durch den Capability Index von Epoch untermauert:
Einer der positivsten Aspekte chinesischer Modelle ist aber sicher ihre Veröffentlichungsstrategie. Denn im Gegensatz zu den US-Firmen erscheinen auch deren Top-Modelle als Open-Source-Modelle mit ausgiebiger Dokumentation. Das heißt: Sowohl Forschungsunterlagen, Code zum Ausführen als auch die Modellparameter können frei heruntergeladen werden und die Modelle zu reinen Hardware- und Stromkostenpreis betrieben werden. Unabhängige Dienste wie OpenRouter bieten diese Modelle auch direkt als API an.
Schaut man sich dagegen die Open-Source-Modelle der amerikanischen Pendants an, sieht man eine massive Diskrepanz zu den chinesischen Modellen:
Die amerikanischen Anbieter achten stark darauf, ihre Monetarisierung nicht zu gefährden. Kaum einer von ihnen veröffentlicht regelmäßig große Open-Source-Modelle.
Von Microsoft kommen die Phi-Modelle aus der Forschungsabteilung, sie sind jedoch zu klein, um wirklich nützlich zu sein. Meta hat sich nach dem Llama-4-Desaster vor einem Jahr eine Pause gegönnt und bislang kein neues Modell veröffentlicht. GPT-OSS war im August 2025 das erste OpenAI-Release seit sieben Jahren und ist im Vergleich zu den chinesischen Modellen mittlerweile ebenfalls veraltet. xAI, die Firma von Elon Musk, will ihre alten Modelle regelmäßig zur Verfügung stellen. Grok-2 stammt aus dem Jahr 2024 und ist damit inzwischen ebenfalls veraltet. Anthropic hat bislang kein einziges Modell veröffentlicht.
Richtig ernst zu nehmen sind derzeit nur zwei Anbieter: Google und NVIDIA. Gemma 4 von Google war in diesem Jahr mit nur 31 Milliarden Parametern ein kleiner Überraschungshit, weil es bereits Agentenaufgaben auf Studentenniveau bewältigen kann. Einen kleinen Lichtblick liefert ausgerechnet NVIDIA: Das Unternehmen veröffentlicht konsequent solide größere Modelle.
Doch auch hier bleibt die Einschränkung: Google wird kaum ein Modell veröffentlichen, das den eigenen Gemini-Modellen ernsthaft Konkurrenz macht. Und NVIDIA versteht seine Modelle vor allem als Forschungs- und Demonstrationsprojekte für die eigene Hardware.
Die Liste aus Europa ist übrigens recht überschaubar:
Die französische Firma Mistral veröffentlicht, ähnlich wie chinesische Anbieter, ebenfalls regelmäßig ihre Top-Modelle. Laut Benchmarks kommen diese jedoch noch nicht an die chinesischen Modelle heran.
Sollte man chinesische Modelle also im Blick behalten? Die Antwort lautet vermutlich: ja. Denn chinesische Open-Source-Modelle sind vielleicht noch nicht ganz so gut wie die besten amerikanischen Modelle, aber für viele Aufgaben bereits „gut genug“.
Berücksichtigt man außerdem die effektiven Preissteigerungen und Lastprobleme von OpenAI und Anthropic in den letzten Monaten, könnten chinesische Open-Source-KI-Modelle schneller ökonomisch attraktiv werden, als die USA darauf reagieren können. Wenn Amerika zudem kein nachhaltiges Modell für Open-Source-KI findet, könnte es dazu kommen, dass der zukünftige AI-Stack auf chinesischer Technologie beruht.
Ein Beitrag von
ist Lead Software Engineer bei QAware und begleitet sowie berät Projekte insbesondere bei der Gestaltung KI-gestützter Anwendungen, tragfähiger Softwarearchitekturen und technologischer [...]

