
 News
News
 News
News
Unser nagelneuer KI-Chatbot: Er lebt!
Ekkehard Schmider
 Blog
Blog 
by Victor Wolf, Lars Kleinschmidt, Martin Siehler & Simon Siedersleben I 1221 words – 6 min read
MLOps is the abbreviation for Machine Learning Operations and is a paradigm that aims to implement and maintain machine learning models reliably and efficiently. MLOps differs from classic DevOps, in particular, in that it integrates models and data in the development process as well as operations. One challenge is that data and models can be very large, which makes it difficult to actively develop and maintain these systems. At its best, MLOps not only orchestrates the management of big data and complex models but also facilitates collaboration between data scientists, developers, and operations engineers.
More than ever before, the influence of AI can be felt in today’s society. In the project world, too, there are currently numerous AI projects or projects that can be optimized using AI, be it in facial recognition, product recommendation, anomaly detection, or chatbots. That is why we have developed a blueprint as part of our AI Guild that optimally integrates AI into software development.
In addition to building up knowledge on this topic, we chose a practical approach and set ourselves the goal of tackling a simple ML problem using typical MLOps techniques and recording it in a Proof of Concept (PoC). Above all, it was important for us to be able to design the pipeline ourselves and operate it in a cloud managed by us.
The first question arose immediately: Which technologies do we actually want to use to build and deploy this pipeline? After a quick Google search, we directly found numerous solutions that promised simple deployment of MLOps with a high degree of adaptability to cloud and project conditions. So we simply followed these approaches and tested various frameworks. Unfortunately, we soon realized that we had fallen victim to promises that were far too high. Some of the solutions were technically far too immature or not as flexible to use as we had hoped. ZenML was a typical example of this. Locally, we were able to quickly set up a pipeline that could solve our problem. The significant challenges arose when we attempted to deploy and operate this pipeline in the cloud. The seemingly simple deployment functionality led to numerous errors, and after a few attempts to fix them and posting issues on GitHub, we made no progress until we put the project aside again. We made another attempt with TFX. TFX is a TensorFlow execution framework that is based on Kubeflow Pipelines. This solution works similarly to Kubeflow Pipelines and adds an abstraction layer on top. This allowed us to deploy pipelines in the cloud. However, the added value compared to Kubeflow Pipelines was too low for us.
Nevertheless, this brought us one step closer to our decision. So why not just use Kubeflow Pipelines directly? With Kubeflow Pipelines, you can easily define your pipelines and deploy them directly on a Kubeflow cluster. Kubeflow itself is based directly on the Kubernetes stack and therefore runs cloud-agnostic. For this solution, we needed a little more customization and configuration to wire the components. However, this also gave us direct influence on the functionality we needed for our pipeline. In the end, we started to build our own MLOps framework/blueprint based on Kubeflow pipelines. Now we have full control over the functionality and can react more easily in case of problems.
With that, we set out to tackle the planned PoC.
To validate the decision for Kubeflow, we developed a Proof of Concept (PoC) pipeline to get to know the functionality of Kubeflow in detail. We used a simple TensorFlow model (Fashion MNIST) for this.
We developed two alternative variants for execution and deployment. One variant uses a classic Kubeflow instance, which we run in the Google Kubernetes Engine (GKE), while the other uses Vertex AI. Vertex AI can run Kubeflow pipelines with little administrative overhead.
The Vertex AI variant is well suited if you want to quickly get into the intricacies of Kubeflow without having to worry about a Kubeflow instance.
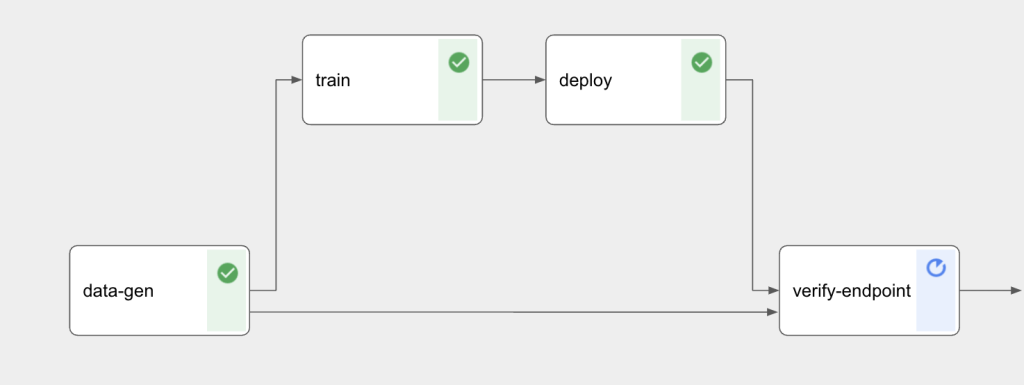
However, in terms of independence from cloud providers, a separate Kubeflow instance often makes more sense. The pipeline performs four steps:
The data for training and evaluating the model must be provided at the beginning. In this case, the data is loaded from the Keras Fashion-MNIST data set. Alternatively, it can also be loaded from CSV files, databases or other data sources.
The model is trained. In this case, TensorFlow is used for training.
However, the functionality is so open by design that any type of model can be trained. The pipeline stores the trained model in a Google Cloud Bucket.
To verify the model’s accuracy and assess its quality relative to previous versions, tests are carried out in this step using the test data collected in step one. Metrics such as accuracy can be collected from this. If the model falls below certain minimum values or is worse than the previous one, it can be rejected so that the old one remains available.
The model is deployed to an endpoint using a serving container, which is either pre-built (e.g. the TensorFlow Serving Container) or can be created by the user. Either Vertex AI Serving can be used for this, or the container can be deployed in the GKE cluster already used for Kubeflow.
We are very satisfied with the functionalities offered. A third-party model was integrated in a very short time using our PoC. Kubeflow is versatile and can be used sensibly. The four steps implemented in the PoC represent the minimum for our use case.
However, further steps can easily be added.
In our quest to realize the ideal MLOps ecosystem, we have used the findings from our PoC to consider other key aspects. One critical point is that our current PoC relies heavily on Google Cloud components. Therefore, we plan to develop a universal blueprint that is not only cloud-agnostic and vendor-independent, but also easy to configure and integrate. The diagram provides an overview of the planned components of the blueprint.
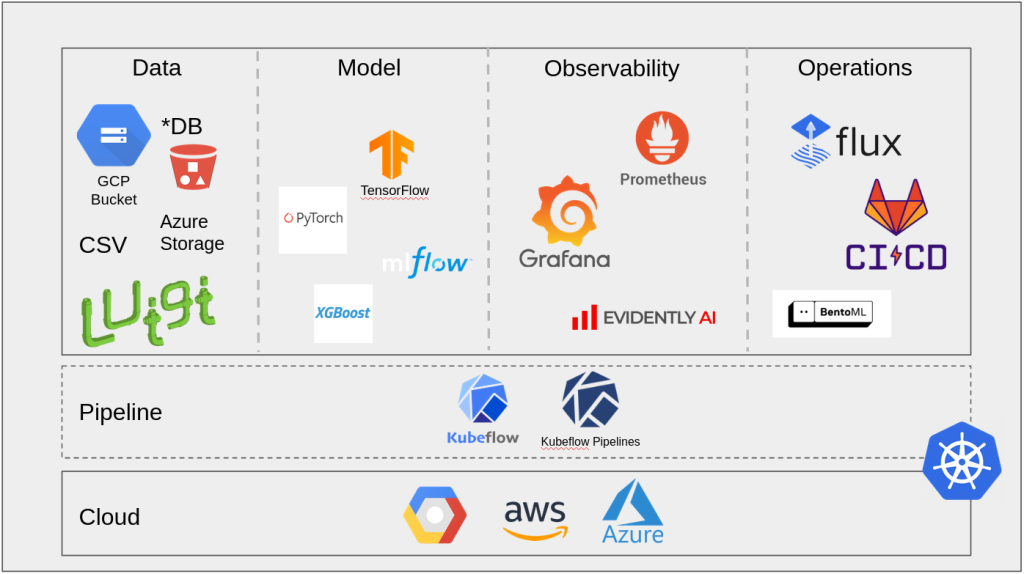
Our MLOps Blueprint Cloud Stack
We intend to extend our PoC with observability components using a Prometheus Grafana stack. Evidently AI could also be used to collect ML-specific metrics. In the area of Continuous Delivery, we are also aiming for an improvement to achieve a stronger focus on GitOps. This could be done by implementing Flux. We are also planning to support our current serving container with a serving framework. BentoML would be an option here. In the data segment, we would like to integrate several configurable data sources. Although the model aspect is largely covered by our PoC, we see potential for optimization through the use of an efficient model registry such as MLflow.
We have chosen Kubeflow as the foundation for our entire MLOps stack. This is due to its Kubernetes-native features, which ensure a certain independence from vendors, as well as the positive experiences we have already had with Kubeflow in our PoC
Our next goal is to implement this universal blueprint. This should make it possible to support the most diverse ML use cases with simple configurations. This paves the way for the productive use of ML systems at QAware by providing a flexible and robust basis for various applications.


